Introducing S1
Our cutting-edge text-to-speech model that performs like voice actors
We are incredibly excited to unveil OpenAudio S1, a cutting-edge text-to-speech (TTS) model that redefines the boundaries of voice generation. Trained on an extensive dataset of over 2 million hours of audio, OpenAudio S1 delivers unparalleled naturalness, expressiveness, and instruction-following capabilities.
The State-of-the-Art in Voice Synthesis
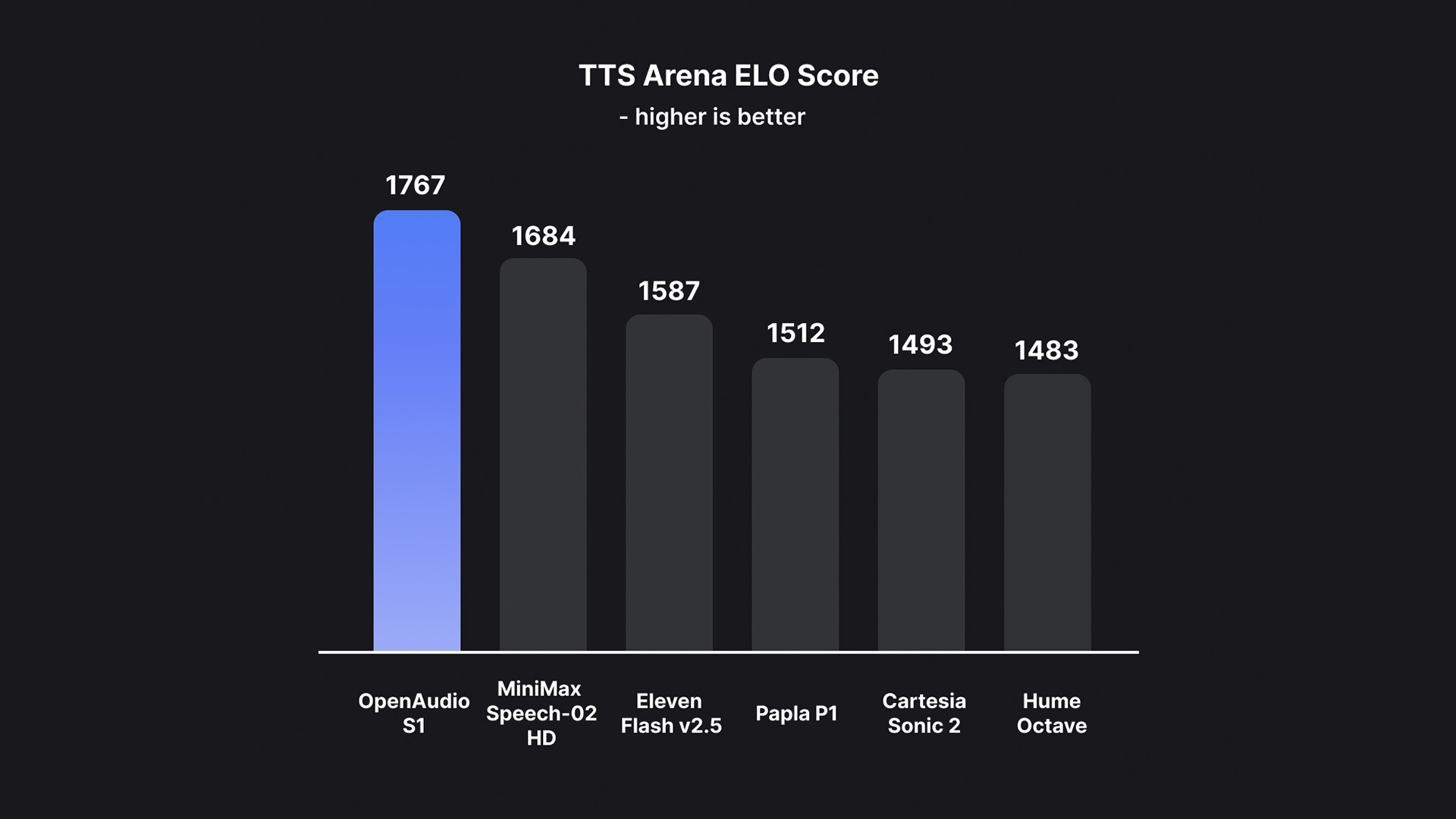
HuggingFace TTS-Arena-V2 ELO score as of June 3rd, 2025.
By utilizing our largest dataset to date, scaling our model to 4B parameters, incorporating our in-house reward modeling, and applying RLHF (GRPO) training, we have overcome the instability of modeling both semantic and acoustic information in a single model.
This eliminates artifacts and incorrect words that result from losing information with semantic-only models, which most other models employ. This approach allows our model to greatly outperform previous models in audio quality, emotion, and speaker similarity.
We achieved not only the world's best WER (word error rate) and CER (character error rate), but also ranked #1 in Human Subjective Evaluation on HuggingFace TTS-Arena-V2.
Seed TTS Eval results based on OpenAI GPT-4o transcription:
- S1 WER: 0.008, CER: 0.004
- S1-mini WER: 0.011, CER: 0.005
Unparalleled Control Like Voice Actors
What truly sets OpenAudio S1 apart is its sophisticated understanding and rendition of human emotion and vocal nuances. The model supports a rich set of markers to precisely control the synthesized speech:
We trained our own speech-to-text model (to be released soon) to caption audio with emotion, tone, speaker information, and more. It achieves state-of-the-art performance in both emotion and tone recognition.
(speaker 1) (concerned) Honey, what's wrong?
(speaker 2) (pretend to be tough) Nothing. I,I, I just said goodbye to Sanjay. We broke up.
(speaker 1) (drag) No.
(speaker 2) No. It's, it's great. We're, we're, we're both going to school unencumbered and ready to focus. It's the smart thing to do. We both feel really good about it.
(speaker 1) You don't look like you feel good.
(speaker 2) Well, yeah, he was, he was sadder than I imagined. So, being strong for the both of us, which he said he admires.
Example of audio captioning by our speech-to-text model.
Using this technology, we captioned over 100k hours of audio to train our TTS model to follow instructions. Here are some examples:
1. Emotional Markers: Infuse speech with a wide spectrum of emotions such as (angry), (sad), (excited), (surprised), (sarcastic), (joyful), (empathetic), and many more.
2. Tone Markers: Adjust the delivery style with markers like (in a hurry tone), (shouting), (screaming), (whispering), and (soft tone).
3. Special Markers: Incorporate human-like vocalizations and events, including (laughing), (chuckling), (sobbing), (sighing), (panting), and even (crowd laughing).
To further enhance realism, specific onomatopoeia can be used with corresponding markers:
• Laughing: Ha,ha,ha
• Chuckling: Hmm,hmm
Truly Accessible Voice Technology
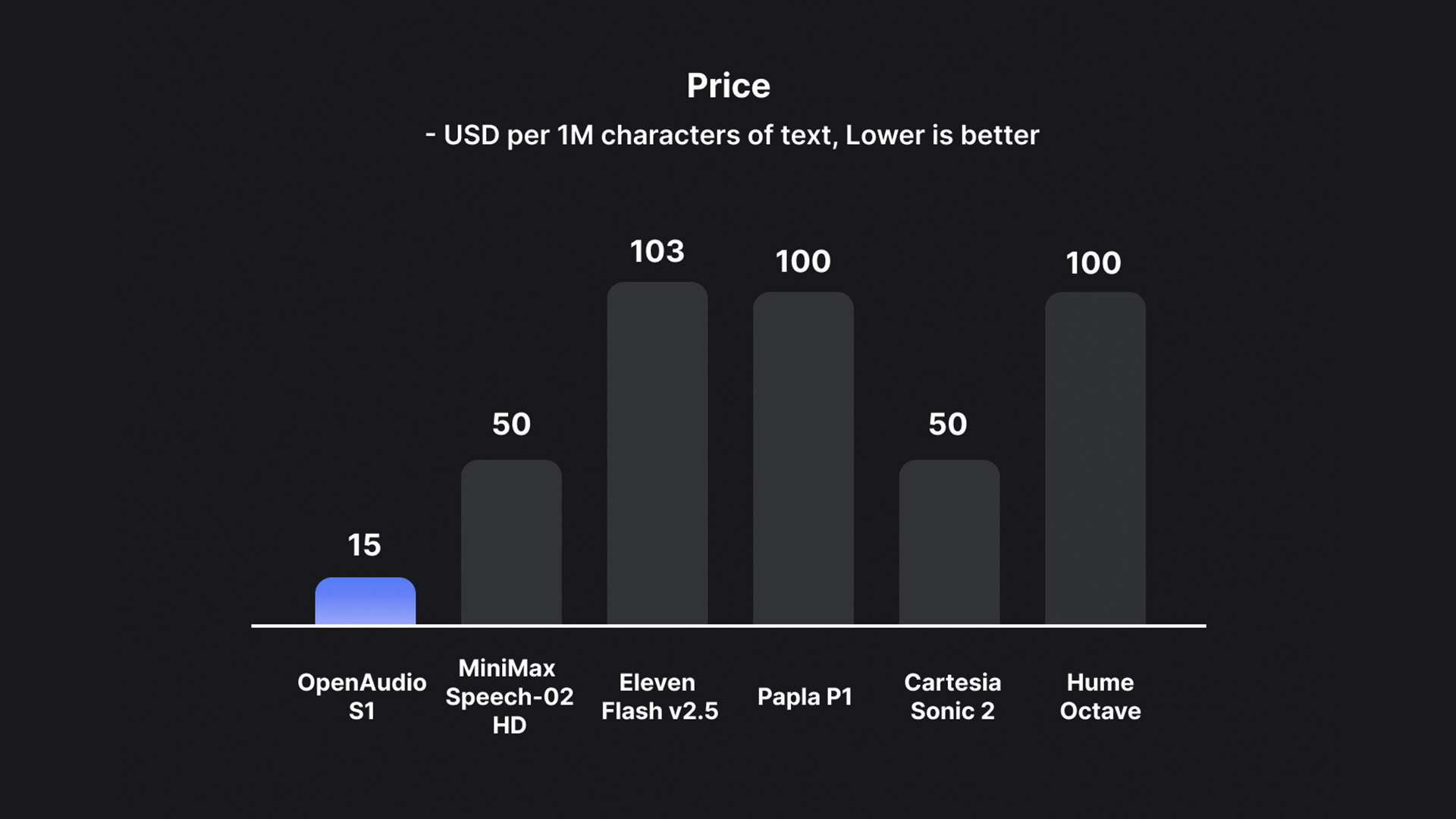
OpenAudio S1 is the most affordable TTS model on the market. Source: Artificial Analytics
Text-to-speech models are significantly more expensive than language models today. This greatly limits the accessibility of voice generation, especially for high-volume applications or budget-conscious developers. We make state-of-the-art technology accessible to everyone—this is the first state-of-the-art model priced at just $15/million bytes (~$0.8/hour).
By continuously improving our training pipeline and inference architecture, we're committed to further reducing the cost of OpenAudio S1 to make it even more accessible. This is a crucial step toward making AI the foundation of next-generation human-computer interaction.
Truly Global Voice Support
OpenAudio S1 offers native support for a wide array of languages, enabling creators and developers to reach global audiences with consistent, high-quality voice output. Supported languages include:
English, Chinese, Japanese, German, French, Spanish, Korean, Arabic, Russian, Dutch, Italian, Polish, Portuguese
Model Variants
OpenAudio S1 comes in two main variants:
• S1 (4B): The full-scale flagship model, offering the richest and most nuanced performance.
• S1-mini (0.5B): A highly efficient, distilled version of S1, designed for applications where resource optimization is key without significant compromise on quality.
OpenAudio S1 leverages the Qwen3 architecture and is fundamentally a native multimodal model capable of TTS, STT, TextQA, and AudioQA (though currently, only the TTS capabilities are being released).
The audio encoding and decoding utilize a Descript Audio Codec-like architecture, trained from scratch and enhanced with a transformer for superior text modeling.
The online RLHF, specifically using an Online GRPO approach, has been instrumental in achieving its state-of-the-art performance.
Get Started with OpenAudio S1
We believe OpenAudio S1 will empower a new generation of voice-enabled applications and experiences. Experience OpenAudio S1 firsthand at the Fish Audio Playground
About OpenAudio
OpenAudio is the Research Lab of Hanabi AI Inc., and Fish Audio is our product platform through which we bring these innovations to the community. We are committed to advancing the field of audio synthesis and look forward to seeing what you create with OpenAudio S1!